Note
Click here to download the full example code
4. Dive deep into Training a Simple Pose Model on COCO Keypoints¶
In this tutorial, we show you how to train a pose estimation model 1 on the COCO dataset.
First let’s import some necessary modules.
from __future__ import division
import time, logging, os, math
import numpy as np
import mxnet as mx
from mxnet import gluon, nd
from mxnet import autograd as ag
from mxnet.gluon import nn
from mxnet.gluon.data.vision import transforms
from gluoncv.data import mscoco
from gluoncv.model_zoo import get_model
from gluoncv.utils import makedirs, LRScheduler
from gluoncv.data.transforms.presets.simple_pose import SimplePoseDefaultTrainTransform
from gluoncv.utils.metrics import HeatmapAccuracy
Loading the data¶
We can load COCO Keypoints dataset with their official API
train_dataset = mscoco.keypoints.COCOKeyPoints('~/.mxnet/datasets/coco',
splits=('person_keypoints_train2017'))
Out:
loading annotations into memory...
Done (t=10.18s)
creating index...
index created!
The dataset object enables us to retrieve images containing a person, the person’s keypoints, and meta-information.
Following the original paper, we resize the input to be (256, 192).
For augmentation, we randomly scale, rotate or flip the input.
Finally we normalize it with the standard ImageNet statistics.
The COCO keypoints dataset contains 17 keypoints for a person.
Each keypoint is annotated with three numbers (x, y, v), where x and y
mark the coordinates, and v indicates if the keypoint is visible.
For each keypoint, we generate a gaussian kernel centered at the (x, y) coordinate, and use
it as the training label. This means the model predicts a gaussian distribution on a feature map.
transform_train = SimplePoseDefaultTrainTransform(num_joints=train_dataset.num_joints,
joint_pairs=train_dataset.joint_pairs,
image_size=(256, 192), heatmap_size=(64, 48),
scale_factor=0.30, rotation_factor=40, random_flip=True)
Now we can define our data loader with the dataset and transformation. We will iterate
over train_data in our training loop.
batch_size = 32
train_data = gluon.data.DataLoader(
train_dataset.transform(transform_train),
batch_size=batch_size, shuffle=True, last_batch='discard', num_workers=0)
Deconvolution Layer¶
A deconvolution layer enlarges the feature map size of the input, so that it can be seen as a layer upsamling the input feature map.
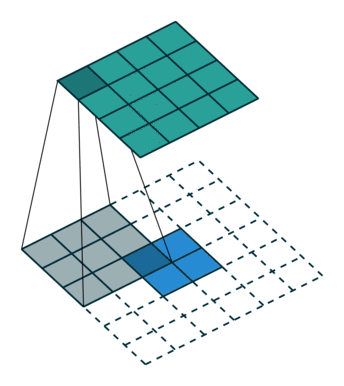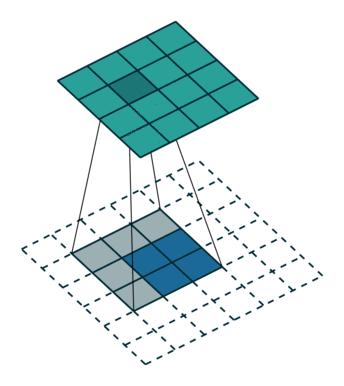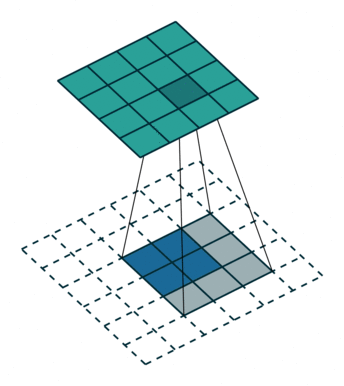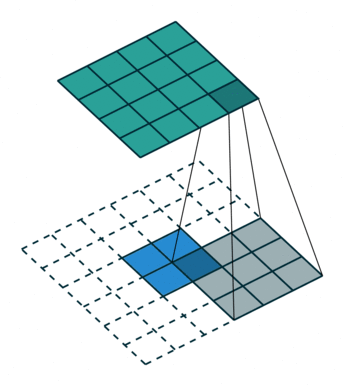
In the above image, the blue map is the input feature map, and the cyan map is the output.
In a ResNet model, the last feature map shrinks its height and width to be only 1/32 of the input. It may
be too small for a heatmap prediction. However if followed by several deconvolution layers, the feature map
can have a larger size thus easier to make the prediction.
Model Definition¶
A Simple Pose model consists of a main body of a resnet, and several deconvolution layers. Its final layer is a convolution layer predicting one heatmap for each keypoint.
Let’s take a look at the smallest one from the GluonCV Model Zoo, using ResNet18 as its base model.
We load the pre-trained parameters for the ResNet18 layers,
and initialize the deconvolution layer and the final convolution layer.
Out:
Downloading /root/.mxnet/models/resnet18_v1b-2d9d980c.zip from https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/models/resnet18_v1b-2d9d980c.zip...
0%| | 0/42432 [00:00<?, ?KB/s]
0%| | 101/42432 [00:00<00:50, 846.11KB/s]
1%|1 | 509/42432 [00:00<00:17, 2357.30KB/s]
5%|5 | 2184/42432 [00:00<00:05, 7637.95KB/s]
20%|#9 | 8294/42432 [00:00<00:01, 26447.47KB/s]
37%|###7 | 15769/42432 [00:00<00:00, 42603.71KB/s]
53%|#####2 | 22424/42432 [00:00<00:00, 50332.53KB/s]
74%|#######3 | 31349/42432 [00:00<00:00, 62624.99KB/s]
93%|#########2| 39433/42432 [00:00<00:00, 68287.19KB/s]
42433KB [00:00, 47641.70KB/s]
We can take a look at the summary of the model
Out:
--------------------------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================================
Input (1, 3, 256, 192) 0
Conv2D-1 (1, 64, 128, 96) 9408
BatchNormCudnnOff-2 (1, 64, 128, 96) 256
Activation-3 (1, 64, 128, 96) 0
MaxPool2D-4 (1, 64, 64, 48) 0
Conv2D-5 (1, 64, 64, 48) 36864
BatchNormCudnnOff-6 (1, 64, 64, 48) 256
Activation-7 (1, 64, 64, 48) 0
Conv2D-8 (1, 64, 64, 48) 36864
BatchNormCudnnOff-9 (1, 64, 64, 48) 256
Activation-10 (1, 64, 64, 48) 0
BasicBlockV1b-11 (1, 64, 64, 48) 0
Conv2D-12 (1, 64, 64, 48) 36864
BatchNormCudnnOff-13 (1, 64, 64, 48) 256
Activation-14 (1, 64, 64, 48) 0
Conv2D-15 (1, 64, 64, 48) 36864
BatchNormCudnnOff-16 (1, 64, 64, 48) 256
Activation-17 (1, 64, 64, 48) 0
BasicBlockV1b-18 (1, 64, 64, 48) 0
Conv2D-19 (1, 128, 32, 24) 73728
BatchNormCudnnOff-20 (1, 128, 32, 24) 512
Activation-21 (1, 128, 32, 24) 0
Conv2D-22 (1, 128, 32, 24) 147456
BatchNormCudnnOff-23 (1, 128, 32, 24) 512
Conv2D-24 (1, 128, 32, 24) 8192
BatchNormCudnnOff-25 (1, 128, 32, 24) 512
Activation-26 (1, 128, 32, 24) 0
BasicBlockV1b-27 (1, 128, 32, 24) 0
Conv2D-28 (1, 128, 32, 24) 147456
BatchNormCudnnOff-29 (1, 128, 32, 24) 512
Activation-30 (1, 128, 32, 24) 0
Conv2D-31 (1, 128, 32, 24) 147456
BatchNormCudnnOff-32 (1, 128, 32, 24) 512
Activation-33 (1, 128, 32, 24) 0
BasicBlockV1b-34 (1, 128, 32, 24) 0
Conv2D-35 (1, 256, 16, 12) 294912
BatchNormCudnnOff-36 (1, 256, 16, 12) 1024
Activation-37 (1, 256, 16, 12) 0
Conv2D-38 (1, 256, 16, 12) 589824
BatchNormCudnnOff-39 (1, 256, 16, 12) 1024
Conv2D-40 (1, 256, 16, 12) 32768
BatchNormCudnnOff-41 (1, 256, 16, 12) 1024
Activation-42 (1, 256, 16, 12) 0
BasicBlockV1b-43 (1, 256, 16, 12) 0
Conv2D-44 (1, 256, 16, 12) 589824
BatchNormCudnnOff-45 (1, 256, 16, 12) 1024
Activation-46 (1, 256, 16, 12) 0
Conv2D-47 (1, 256, 16, 12) 589824
BatchNormCudnnOff-48 (1, 256, 16, 12) 1024
Activation-49 (1, 256, 16, 12) 0
BasicBlockV1b-50 (1, 256, 16, 12) 0
Conv2D-51 (1, 512, 8, 6) 1179648
BatchNormCudnnOff-52 (1, 512, 8, 6) 2048
Activation-53 (1, 512, 8, 6) 0
Conv2D-54 (1, 512, 8, 6) 2359296
BatchNormCudnnOff-55 (1, 512, 8, 6) 2048
Conv2D-56 (1, 512, 8, 6) 131072
BatchNormCudnnOff-57 (1, 512, 8, 6) 2048
Activation-58 (1, 512, 8, 6) 0
BasicBlockV1b-59 (1, 512, 8, 6) 0
Conv2D-60 (1, 512, 8, 6) 2359296
BatchNormCudnnOff-61 (1, 512, 8, 6) 2048
Activation-62 (1, 512, 8, 6) 0
Conv2D-63 (1, 512, 8, 6) 2359296
BatchNormCudnnOff-64 (1, 512, 8, 6) 2048
Activation-65 (1, 512, 8, 6) 0
BasicBlockV1b-66 (1, 512, 8, 6) 0
Conv2DTranspose-67 (1, 256, 16, 12) 2097152
BatchNormCudnnOff-68 (1, 256, 16, 12) 1024
Activation-69 (1, 256, 16, 12) 0
Conv2DTranspose-70 (1, 256, 32, 24) 1048576
BatchNormCudnnOff-71 (1, 256, 32, 24) 1024
Activation-72 (1, 256, 32, 24) 0
Conv2DTranspose-73 (1, 256, 64, 48) 1048576
BatchNormCudnnOff-74 (1, 256, 64, 48) 1024
Activation-75 (1, 256, 64, 48) 0
Conv2D-76 (1, 17, 64, 48) 4369
SimplePoseResNet-77 (1, 17, 64, 48) 0
================================================================================
Parameters in forward computation graph, duplicate included
Total params: 15387857
Trainable params: 15376721
Non-trainable params: 11136
Shared params in forward computation graph: 0
Unique parameters in model: 15387857
--------------------------------------------------------------------------------
Note
The Batch Normalization implementation from cuDNN has a negative impact on the model training, as reported in these issues 2, 3 .
Since similar behavior is observed, we implement a BatchNormCudnnOff layer as a temporary solution.
This layer doesn’t call the Batch Normalization layer from cuDNN, thus gives better results.
Training Setup¶
Next, we can set up everything for the training.
Loss:
We apply a weighted
L2Losson the predicted heatmap, where the weight is 1 if the keypoint is visible, otherwise is 0.
L = gluon.loss.L2Loss()
Learning Rate Schedule and Optimizer:
We use an initial learning rate at 0.001, and divide it by 10 at the 90th and 120th epoch.
num_training_samples = len(train_dataset)
num_batches = num_training_samples // batch_size
lr_scheduler = LRScheduler(mode='step', base_lr=0.001,
iters_per_epoch=num_batches, nepochs=140,
step_epoch=(90, 120), step_factor=0.1)
For this model we use adam as the optimizer.
trainer = gluon.Trainer(net.collect_params(), 'adam', {'lr_scheduler': lr_scheduler})
Metric
The metric for this model is called heatmap accuracy, i.e. it compares the keypoint heatmaps from the prediction and groundtruth and check if the center of the gaussian distributions are within a certain distance.
Training Loop¶
Since we have all necessary blocks, we can now put them together to start the training.
net.hybridize(static_alloc=True, static_shape=True)
for epoch in range(1):
metric.reset()
for i, batch in enumerate(train_data):
if i > 0:
break
data = gluon.utils.split_and_load(batch[0], ctx_list=[context], batch_axis=0)
label = gluon.utils.split_and_load(batch[1], ctx_list=[context], batch_axis=0)
weight = gluon.utils.split_and_load(batch[2], ctx_list=[context], batch_axis=0)
with ag.record():
outputs = [net(X) for X in data]
loss = [L(yhat, y, w) for yhat, y, w in zip(outputs, label, weight)]
for l in loss:
l.backward()
trainer.step(batch_size)
metric.update(label, outputs)
break
Due to limitation on the resources, we only train the model for one batch in this tutorial.
Please checkout the full training script to reproduce our results.
References¶
- 1
Xiao, Bin, Haiping Wu, and Yichen Wei. “Simple baselines for human pose estimation and tracking.” Proceedings of the European Conference on Computer Vision (ECCV). 2018.
- 2
https://github.com/Microsoft/human-pose-estimation.pytorch/issues/48
- 3
Total running time of the script: ( 1 minutes 43.931 seconds)