Note
Click here to download the full example code
08. Finetune a pretrained detection model¶
Fine-tuning is commonly used approach to transfer previously trained model to a new dataset. It is especially useful if the targeting new dataset is relatively small.
Finetuning from pre-trained models can help reduce the risk of overfitting. Finetuned model may also generalizes better if the previously used dataset is in the similar domain of the new dataset.
This tutorial opens up a good approach for fine-tuning object detection models provided by GluonCV. More Specifically, we show how to use a customized Pikachu dataset and illustrate the finetuning fundamentals step by step. You will be familiarize the steps and modify it to fit your own object detection projects.
import time
from matplotlib import pyplot as plt
import numpy as np
import mxnet as mx
from mxnet import autograd, gluon
import gluoncv as gcv
from gluoncv.utils import download, viz
Pikachu Dataset¶
First we will start with a nice Pikachu dataset generated by rendering 3D models on random real-world scenes. You can refer to Prepare custom datasets for object detection for tutorial of how to create your own datasets.
Out:
Downloading pikachu_train.rec from https://apache-mxnet.s3-accelerate.amazonaws.com/gluon/dataset/pikachu/train.rec...
0%| | 0/85604 [00:00<?, ?KB/s]
0%| | 99/85604 [00:00<01:42, 831.29KB/s]
1%| | 516/85604 [00:00<00:35, 2398.94KB/s]
3%|2 | 2183/85604 [00:00<00:10, 7664.70KB/s]
10%|9 | 8264/85604 [00:00<00:02, 26420.86KB/s]
18%|#7 | 15012/85604 [00:00<00:01, 40183.06KB/s]
27%|##6 | 23009/85604 [00:00<00:01, 53062.78KB/s]
37%|###7 | 31770/85604 [00:00<00:00, 63987.92KB/s]
47%|####6 | 39867/85604 [00:00<00:00, 69271.13KB/s]
56%|#####6 | 48328/85604 [00:00<00:00, 73947.12KB/s]
66%|######6 | 56677/85604 [00:01<00:00, 76859.18KB/s]
76%|#######5 | 64851/85604 [00:01<00:00, 78331.42KB/s]
86%|########5 | 73374/85604 [00:01<00:00, 80412.73KB/s]
95%|#########5| 81454/85604 [00:01<00:00, 80501.35KB/s]
85605KB [00:01, 60629.71KB/s]
Downloading pikachu_train.idx from https://apache-mxnet.s3-accelerate.amazonaws.com/gluon/dataset/pikachu/train.idx...
0%| | 0/11 [00:00<?, ?KB/s]
12KB [00:00, 11259.88KB/s]
We can load dataset using RecordFileDetection
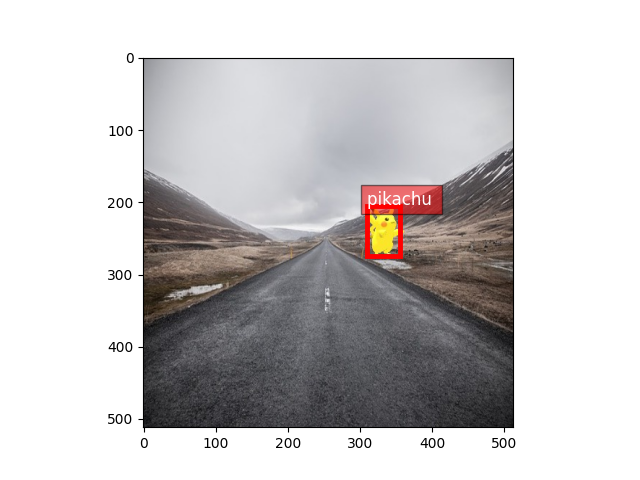
Out:
label: [[309.6292 205.79944 355.75494 274.14044 0. ]]
Pre-trained models¶
Now we can grab a pre-trained model to finetune from. Here we have so many choices from Detection Model Zoo. Again for demo purpose, we choose a fast SSD network with MobileNet1.0 backbone.
net = gcv.model_zoo.get_model('ssd_512_mobilenet1.0_voc', pretrained=True)
Out:
/usr/local/lib/python3.6/dist-packages/mxnet/gluon/block.py:1512: UserWarning: Cannot decide type for the following arguments. Consider providing them as input:
data: None
input_sym_arg_type = in_param.infer_type()[0]
Downloading /root/.mxnet/models/ssd_512_mobilenet1.0_voc-37c18076.zip from https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/models/ssd_512_mobilenet1.0_voc-37c18076.zip...
0%| | 0/50216 [00:00<?, ?KB/s]
0%| | 93/50216 [00:00<01:07, 740.10KB/s]
1%|1 | 518/50216 [00:00<00:21, 2281.86KB/s]
4%|4 | 2180/50216 [00:00<00:06, 7238.43KB/s]
16%|#5 | 7805/50216 [00:00<00:01, 23914.26KB/s]
28%|##8 | 14220/50216 [00:00<00:00, 37073.82KB/s]
45%|####4 | 22564/50216 [00:00<00:00, 51838.35KB/s]
60%|#####9 | 30022/50216 [00:00<00:00, 58948.02KB/s]
76%|#######6 | 38257/50216 [00:00<00:00, 64740.74KB/s]
93%|#########2| 46642/50216 [00:00<00:00, 70499.45KB/s]
50217KB [00:01, 48530.14KB/s]
reset network to predict pikachus!
net.reset_class(classes)
# now the output layers that used to map to VOC classes are now reset to distinguish pikachu (and background).
There is a convenient API for creating custom network with pre-trained weights.
This is equivalent to loading pre-trained model and call net.reset_class.
net = gcv.model_zoo.get_model('ssd_512_mobilenet1.0_custom', classes=classes,
pretrained_base=False, transfer='voc')
Out:
/usr/local/lib/python3.6/dist-packages/mxnet/gluon/block.py:1512: UserWarning: Cannot decide type for the following arguments. Consider providing them as input:
data: None
input_sym_arg_type = in_param.infer_type()[0]
By loading from fully pre-trained models, you are not only loading base network weights (mobilenet for example), but also some additional blocks for object detection specifically.
Pretrained model from detection task is more relevant and adaptive than pretrained_base
network which is usually trained on ImageNet for image classification task.
Therefore finetuning may converge significantly faster and better in some situations.
Finetuning is a new round of training¶
Hint
You will find a more detailed training implementation of SSD here:
Download train_ssd.py
def get_dataloader(net, train_dataset, data_shape, batch_size, num_workers):
from gluoncv.data.batchify import Tuple, Stack, Pad
from gluoncv.data.transforms.presets.ssd import SSDDefaultTrainTransform
width, height = data_shape, data_shape
# use fake data to generate fixed anchors for target generation
with autograd.train_mode():
_, _, anchors = net(mx.nd.zeros((1, 3, height, width)))
batchify_fn = Tuple(Stack(), Stack(), Stack()) # stack image, cls_targets, box_targets
train_loader = gluon.data.DataLoader(
train_dataset.transform(SSDDefaultTrainTransform(width, height, anchors)),
batch_size, True, batchify_fn=batchify_fn, last_batch='rollover', num_workers=num_workers)
return train_loader
train_data = get_dataloader(net, dataset, 512, 16, 0)
Try use GPU for training
Start training(finetuning)
net.collect_params().reset_ctx(ctx)
trainer = gluon.Trainer(
net.collect_params(), 'sgd',
{'learning_rate': 0.001, 'wd': 0.0005, 'momentum': 0.9})
mbox_loss = gcv.loss.SSDMultiBoxLoss()
ce_metric = mx.metric.Loss('CrossEntropy')
smoothl1_metric = mx.metric.Loss('SmoothL1')
for epoch in range(0, 2):
ce_metric.reset()
smoothl1_metric.reset()
tic = time.time()
btic = time.time()
net.hybridize(static_alloc=True, static_shape=True)
for i, batch in enumerate(train_data):
batch_size = batch[0].shape[0]
data = gluon.utils.split_and_load(batch[0], ctx_list=ctx, batch_axis=0)
cls_targets = gluon.utils.split_and_load(batch[1], ctx_list=ctx, batch_axis=0)
box_targets = gluon.utils.split_and_load(batch[2], ctx_list=ctx, batch_axis=0)
with autograd.record():
cls_preds = []
box_preds = []
for x in data:
cls_pred, box_pred, _ = net(x)
cls_preds.append(cls_pred)
box_preds.append(box_pred)
sum_loss, cls_loss, box_loss = mbox_loss(
cls_preds, box_preds, cls_targets, box_targets)
autograd.backward(sum_loss)
# since we have already normalized the loss, we don't want to normalize
# by batch-size anymore
trainer.step(1)
ce_metric.update(0, [l * batch_size for l in cls_loss])
smoothl1_metric.update(0, [l * batch_size for l in box_loss])
name1, loss1 = ce_metric.get()
name2, loss2 = smoothl1_metric.get()
if i % 20 == 0:
print('[Epoch {}][Batch {}], Speed: {:.3f} samples/sec, {}={:.3f}, {}={:.3f}'.format(
epoch, i, batch_size/(time.time()-btic), name1, loss1, name2, loss2))
btic = time.time()
Out:
[Epoch 0][Batch 0], Speed: 8.521 samples/sec, CrossEntropy=11.958, SmoothL1=1.986
[Epoch 0][Batch 20], Speed: 19.758 samples/sec, CrossEntropy=4.358, SmoothL1=1.233
[Epoch 0][Batch 40], Speed: 21.477 samples/sec, CrossEntropy=3.299, SmoothL1=0.968
[Epoch 1][Batch 0], Speed: 20.556 samples/sec, CrossEntropy=1.529, SmoothL1=0.308
[Epoch 1][Batch 20], Speed: 19.868 samples/sec, CrossEntropy=1.613, SmoothL1=0.454
[Epoch 1][Batch 40], Speed: 19.864 samples/sec, CrossEntropy=1.577, SmoothL1=0.453
Save finetuned weights to disk
net.save_parameters('ssd_512_mobilenet1.0_pikachu.params')
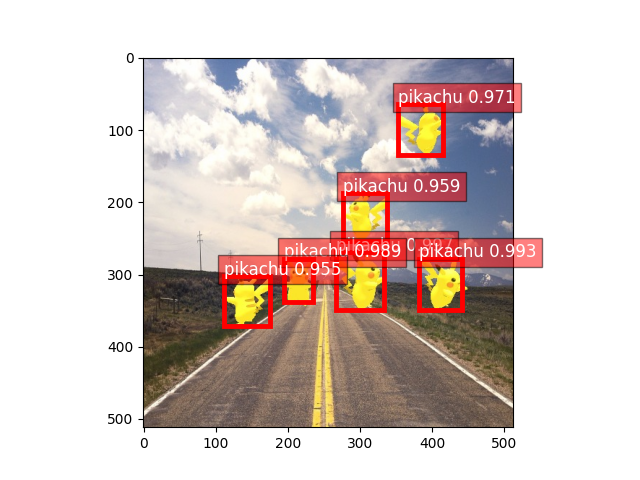
Predict with finetuned model¶
We can test the performance using finetuned weights
test_url = 'https://raw.githubusercontent.com/zackchase/mxnet-the-straight-dope/master/img/pikachu.jpg'
download(test_url, 'pikachu_test.jpg')
net = gcv.model_zoo.get_model('ssd_512_mobilenet1.0_custom', classes=classes, pretrained_base=False)
net.load_parameters('ssd_512_mobilenet1.0_pikachu.params')
x, image = gcv.data.transforms.presets.ssd.load_test('pikachu_test.jpg', 512)
cid, score, bbox = net(x)
ax = viz.plot_bbox(image, bbox[0], score[0], cid[0], class_names=classes)
plt.show()
Out:
Downloading pikachu_test.jpg from https://raw.githubusercontent.com/zackchase/mxnet-the-straight-dope/master/img/pikachu.jpg...
0%| | 0/88 [00:00<?, ?KB/s]
89KB [00:00, 19654.24KB/s]
/usr/local/lib/python3.6/dist-packages/mxnet/gluon/block.py:1512: UserWarning: Cannot decide type for the following arguments. Consider providing them as input:
data: None
input_sym_arg_type = in_param.infer_type()[0]
In two epochs and less than 5 min, we are able to detect pikachus perfectly!
Hint
This finetune tutorial is not limited to SSD, you can extend it to Faster-RCNN, YOLO training by adapting a training blocks in the following examples:
Total running time of the script: ( 1 minutes 33.133 seconds)