Note
Click here to download the full example code
Prepare ADE20K dataset.¶
ADE20K is a scene-centric containing 20 thousands images annotated with 150 object categories. This tutorial help you to download ADE20K and set it up for later experiments.

Hint
You need 2.3 GB free disk space to download and extract this dataset. SSD harddrives are recommended for faster speed. The time it takes to prepare the dataset depends on your Internet connection and disk speed. For example, it takes around 25 mins on an AWS EC2 instance with EBS.
Prepare the dataset¶
We will download and unzip the following files:
File name |
Size |
|---|---|
923 MB |
|
202 MB |
The easiest way is to run this script:
python ade20k.py
If you have already downloaded the above files and unzipped them,
you can set the folder name through --download-dir to avoid
downloading them again. For example
python ade20k.py --download-dir ~/ade_downloads
How to load the dataset¶
Loading images and labels from ADE20K is straight-forward with GluonCV’s dataset utility:
from gluoncv.data import ADE20KSegmentation
train_dataset = ADE20KSegmentation(split='train')
val_dataset = ADE20KSegmentation(split='val')
print('Training images:', len(train_dataset))
print('Validation images:', len(val_dataset))
Out:
Training images: 20210
Validation images: 2000
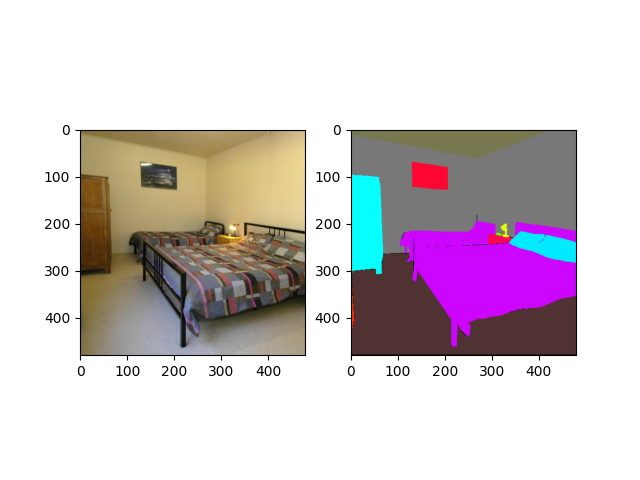
Get the first sample¶
import numpy as np
img, mask = val_dataset[0]
# get pallete for the mask
from gluoncv.utils.viz import get_color_pallete
mask = get_color_pallete(mask.asnumpy(), dataset='ade20k')
mask.save('mask.png')
Visualize data and label¶
from matplotlib import pyplot as plt
import matplotlib.image as mpimg
# subplot 1 for img
fig = plt.figure()
fig.add_subplot(1,2,1)
plt.imshow(img.asnumpy().astype('uint8'))
# subplot 2 for the mask
mmask = mpimg.imread('mask.png')
fig.add_subplot(1,2,2)
plt.imshow(mmask)
# display
plt.show()
Total running time of the script: ( 0 minutes 43.456 seconds)