Note
Click here to download the full example code
2. Dive Deep into Training TSN mdoels on UCF101¶
This is a video action recognition tutorial using Gluon CV toolkit, a step-by-step example. The readers should have basic knowledge of deep learning and should be familiar with Gluon API. New users may first go through A 60-minute Gluon Crash Course. You can Start Training Now or `Dive into Deep`_.
Start Training Now¶
Note
Feel free to skip the tutorial because the training script is self-complete and ready to launch.
Download Full Python Script: train_recognizer.py
Example training command:
# Finetune a pretrained VGG16 model without using temporal segment network.
python train_recognizer.py --model vgg16_ucf101 --num-classes 101 --num-gpus 8 --lr-mode step --lr 0.001 --lr-decay 0.1 --lr-decay-epoch 30,60,80 --num-epochs 80
# Finetune a pretrained VGG16 model using temporal segment network.
python train_recognizer.py --model vgg16_ucf101 --num-classes 101 --num-gpus 8 --num-segments 3 --lr-mode step --lr 0.001 --lr-decay 0.1 --lr-decay-epoch 30,60,80 --num-epochs 80
For more training command options, please run python train_recognizer.py -h
Please checkout the model_zoo for training commands of reproducing the pretrained model.
Network Structure¶
First, let’s import the necessary libraries into python.
from __future__ import division
import argparse, time, logging, os, sys, math
import numpy as np
import mxnet as mx
import gluoncv as gcv
from mxnet import gluon, nd, init, context
from mxnet import autograd as ag
from mxnet.gluon import nn
from mxnet.gluon.data.vision import transforms
from gluoncv.data.transforms import video
from gluoncv.data import UCF101
from gluoncv.model_zoo import get_model
from gluoncv.utils import makedirs, LRSequential, LRScheduler, split_and_load, TrainingHistory
Video action recognition is a classification problem.
Here we pick a simple yet well-performing structure, vgg16_ucf101, for the
tutorial. In addition, we use the the idea of temporal segments (TSN) [Wang16]
to wrap the backbone VGG16 network for adaptation to video domain.
TSN is a widely adopted video classification method. It is proposed to incorporate temporal information from an entire video. The idea is straightforward: we can evenly divide the video into several segments, process each segment individually, obtain segmental consensus from each segment, and perform final prediction. TSN is more like a general algorithm, rather than a specific network architecture. It can work with both 2D and 3D neural networks.
# number of GPUs to use
num_gpus = 1
ctx = [mx.gpu(i) for i in range(num_gpus)]
# Get the model vgg16_ucf101 with temporal segment network, with 101 output classes, without pre-trained weights
net = get_model(name='vgg16_ucf101', nclass=101, num_segments=3)
net.collect_params().reset_ctx(ctx)
print(net)
Out:
ActionRecVGG16(
(features): HybridSequential(
(0): Conv2D(3 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Activation(relu)
(2): Conv2D(64 -> 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Activation(relu)
(4): MaxPool2D(size=(2, 2), stride=(2, 2), padding=(0, 0), ceil_mode=False, global_pool=False, pool_type=max, layout=NCHW)
(5): Conv2D(64 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): Activation(relu)
(7): Conv2D(128 -> 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): Activation(relu)
(9): MaxPool2D(size=(2, 2), stride=(2, 2), padding=(0, 0), ceil_mode=False, global_pool=False, pool_type=max, layout=NCHW)
(10): Conv2D(128 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): Activation(relu)
(12): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): Activation(relu)
(14): Conv2D(256 -> 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): Activation(relu)
(16): MaxPool2D(size=(2, 2), stride=(2, 2), padding=(0, 0), ceil_mode=False, global_pool=False, pool_type=max, layout=NCHW)
(17): Conv2D(256 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): Activation(relu)
(19): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): Activation(relu)
(21): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): Activation(relu)
(23): MaxPool2D(size=(2, 2), stride=(2, 2), padding=(0, 0), ceil_mode=False, global_pool=False, pool_type=max, layout=NCHW)
(24): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): Activation(relu)
(26): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): Activation(relu)
(28): Conv2D(512 -> 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): Activation(relu)
(30): MaxPool2D(size=(2, 2), stride=(2, 2), padding=(0, 0), ceil_mode=False, global_pool=False, pool_type=max, layout=NCHW)
(31): Dense(25088 -> 4096, Activation(relu))
(32): Dropout(p = 0.9, axes=())
(33): Dense(4096 -> 4096, Activation(relu))
(34): Dropout(p = 0.9, axes=())
)
(output): Dense(4096 -> 101, linear)
)
Data Augmentation and Data Loader¶
Data augmentation for video is different from image. For example, if you want to randomly crop a video sequence, you need to make sure all the video frames in this sequence undergo the same cropping process. We provide a new set of transformation functions, working with multiple images. Please checkout the video.py for more details. Most video data augmentation strategies used here are introduced in [Wang15].
transform_train = transforms.Compose([
# Fix the input video frames size as 256×340 and randomly sample the cropping width and height from
# {256,224,192,168}. After that, resize the cropped regions to 224 × 224.
video.VideoMultiScaleCrop(size=(224, 224), scale_ratios=[1.0, 0.875, 0.75, 0.66]),
# Randomly flip the video frames horizontally
video.VideoRandomHorizontalFlip(),
# Transpose the video frames from height*width*num_channels to num_channels*height*width
# and map values from [0, 255] to [0,1]
video.VideoToTensor(),
# Normalize the video frames with mean and standard deviation calculated across all images
video.VideoNormalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
With the transform functions, we can define data loaders for our training datasets.
# Batch Size for Each GPU
per_device_batch_size = 5
# Number of data loader workers
num_workers = 0
# Calculate effective total batch size
batch_size = per_device_batch_size * num_gpus
# Set train=True for training the model. Here we set num_segments to 3 to enable TSN training.
# Make sure you have UCF101 data prepared
# Please checkout the `ucf101.py <../../../../datasets/ucf101.py>`_ for more details.
train_dataset = UCF101(train=True, num_segments=3, transform=transform_train)
print('Load %d training samples.' % len(train_dataset))
train_data = gluon.data.DataLoader(train_dataset, batch_size=batch_size,
shuffle=True, num_workers=num_workers)
Out:
Load 9537 training samples.
Optimizer, Loss and Metric¶
# Learning rate decay factor
lr_decay = 0.1
# Epochs where learning rate decays
lr_decay_epoch = [30, 60, np.inf]
# Stochastic gradient descent
optimizer = 'sgd'
# Set parameters
optimizer_params = {'learning_rate': 0.001, 'wd': 0.0001, 'momentum': 0.9}
# Define our trainer for net
trainer = gluon.Trainer(net.collect_params(), optimizer, optimizer_params)
In order to optimize our model, we need a loss function. For classification tasks, we usually use softmax cross entropy as the loss function.
loss_fn = gluon.loss.SoftmaxCrossEntropyLoss()
For simplicity, we use accuracy as the metric to monitor our training process. Besides, we record metric values, and will print them at the end of training.
train_metric = mx.metric.Accuracy()
train_history = TrainingHistory(['training-acc'])
Training¶
After all the preparations, we can finally start training! Following is the script.
Note
In order to finish the tutorial quickly, we only train for 3 epochs, and 100 iterations per epoch.
In your experiments, we recommend setting epochs=80 for the full UCF101 dataset.
epochs = 3
lr_decay_count = 0
for epoch in range(epochs):
tic = time.time()
train_metric.reset()
train_loss = 0
# Learning rate decay
if epoch == lr_decay_epoch[lr_decay_count]:
trainer.set_learning_rate(trainer.learning_rate*lr_decay)
lr_decay_count += 1
# Loop through each batch of training data
for i, batch in enumerate(train_data):
# Extract data and label
data = split_and_load(batch[0], ctx_list=ctx, batch_axis=0)
label = split_and_load(batch[1], ctx_list=ctx, batch_axis=0)
# AutoGrad
with ag.record():
output = []
for _, X in enumerate(data):
X = X.reshape((-1,) + X.shape[2:])
pred = net(X)
output.append(pred)
loss = [loss_fn(yhat, y) for yhat, y in zip(output, label)]
# Backpropagation
for l in loss:
l.backward()
# Optimize
trainer.step(batch_size)
# Update metrics
train_loss += sum([l.mean().asscalar() for l in loss])
train_metric.update(label, output)
if i == 100:
break
name, acc = train_metric.get()
# Update history and print metrics
train_history.update([acc])
print('[Epoch %d] train=%f loss=%f time: %f' %
(epoch, acc, train_loss / (i+1), time.time()-tic))
# We can plot the metric scores with:
train_history.plot()
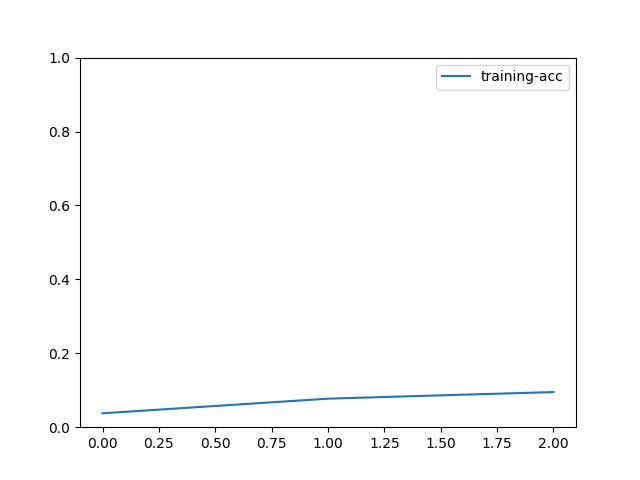
Out:
[Epoch 0] train=0.037624 loss=4.593155 time: 43.816577
[Epoch 1] train=0.077228 loss=4.329765 time: 42.983821
[Epoch 2] train=0.095050 loss=4.159773 time: 43.229185
You can Start Training Now.
If you would like to use a bigger 3D model (e.g., I3D) on a larger dataset (e.g., Kinetics400), feel free to read the next tutorial on Kinetics400.
References¶
- Wang15
Limin Wang, Yuanjun Xiong, Zhe Wang, and Yu Qiao. “Towards Good Practices for Very Deep Two-Stream ConvNets.” arXiv preprint arXiv:1507.02159 (2015).
- Wang16
Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang and Luc Van Gool. “Temporal Segment Networks: Towards Good Practices for Deep Action Recognition.” In European Conference on Computer Vision (ECCV). 2016.
Total running time of the script: ( 2 minutes 11.163 seconds)